Sélectionnez votre langue
")
")

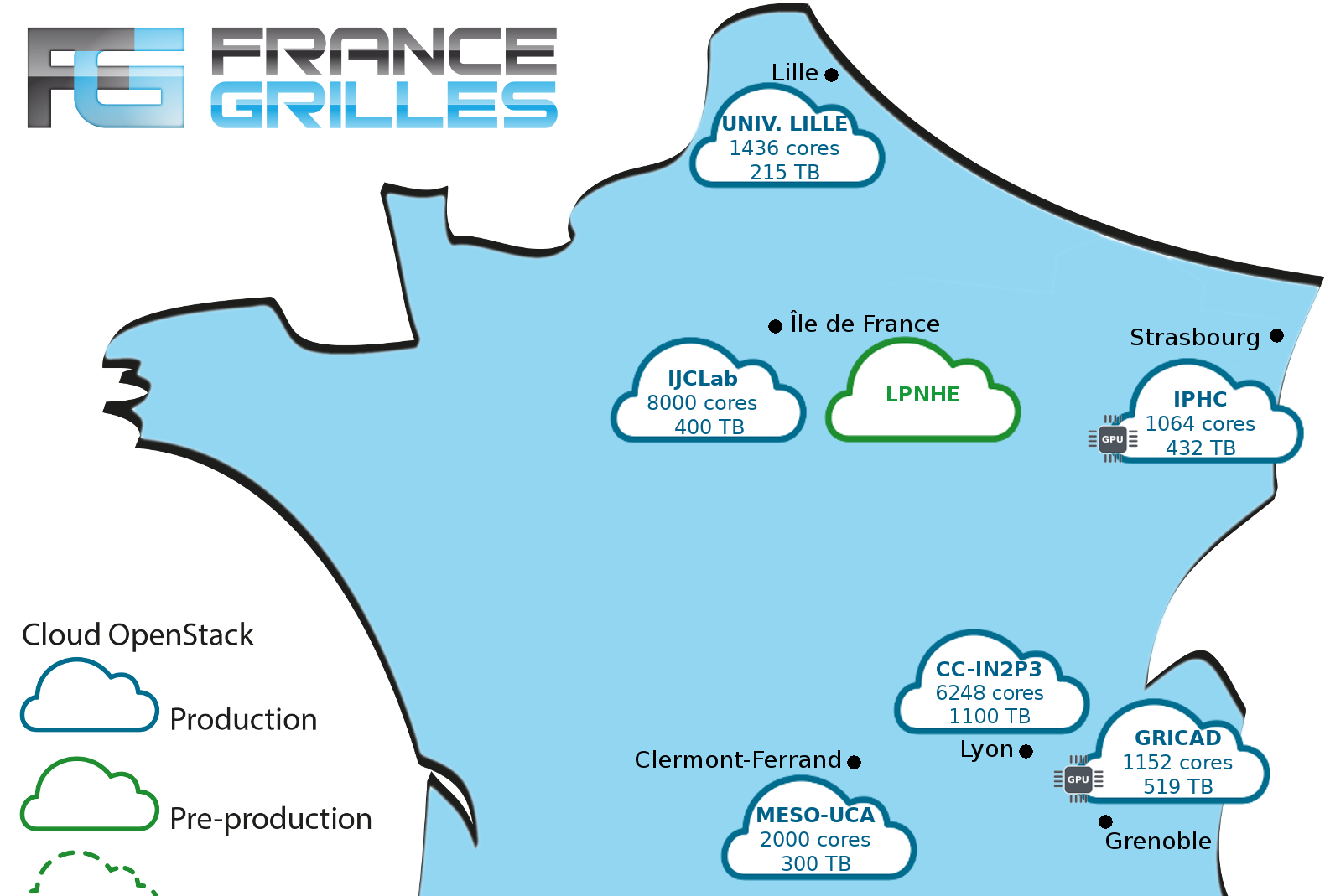
Plateforme SCIGNE
Infrastructure

Man Power
Services

Les chiffres clés
Slots de Calculs
Téraoctets de stockage sur disque
Dernières Actualités

Mise en place d’un nouveau système de refroidissement de type Free-Cooling
Fin février 2023, la plateforme SCIGNE s’est équipée d’un nouvel aéroréfrigérant. Cet équipement, associé au système de refroidissement d’eau, permet de travailler en free-cooling. Il permet...
Atelier Technique EOSC 2022
Le GIS France Grilles co-organise un atelier technique EOSC du 24 au 26 janvier 2023 à l’IPHC (Strasbourg). L’équipe de la plateforme SCIGNE, organisatrice locale de cet événement, vous invite à...

JCAD 2021
Les JCAD sont dédiées à la fois aux utilisateurs et aux experts techniques des infrastructures et des services associés.

Nos Missions
La science en mouvement
Notre historique

Accompagnement

Ressources

Contribution nationale

Contribution européenne
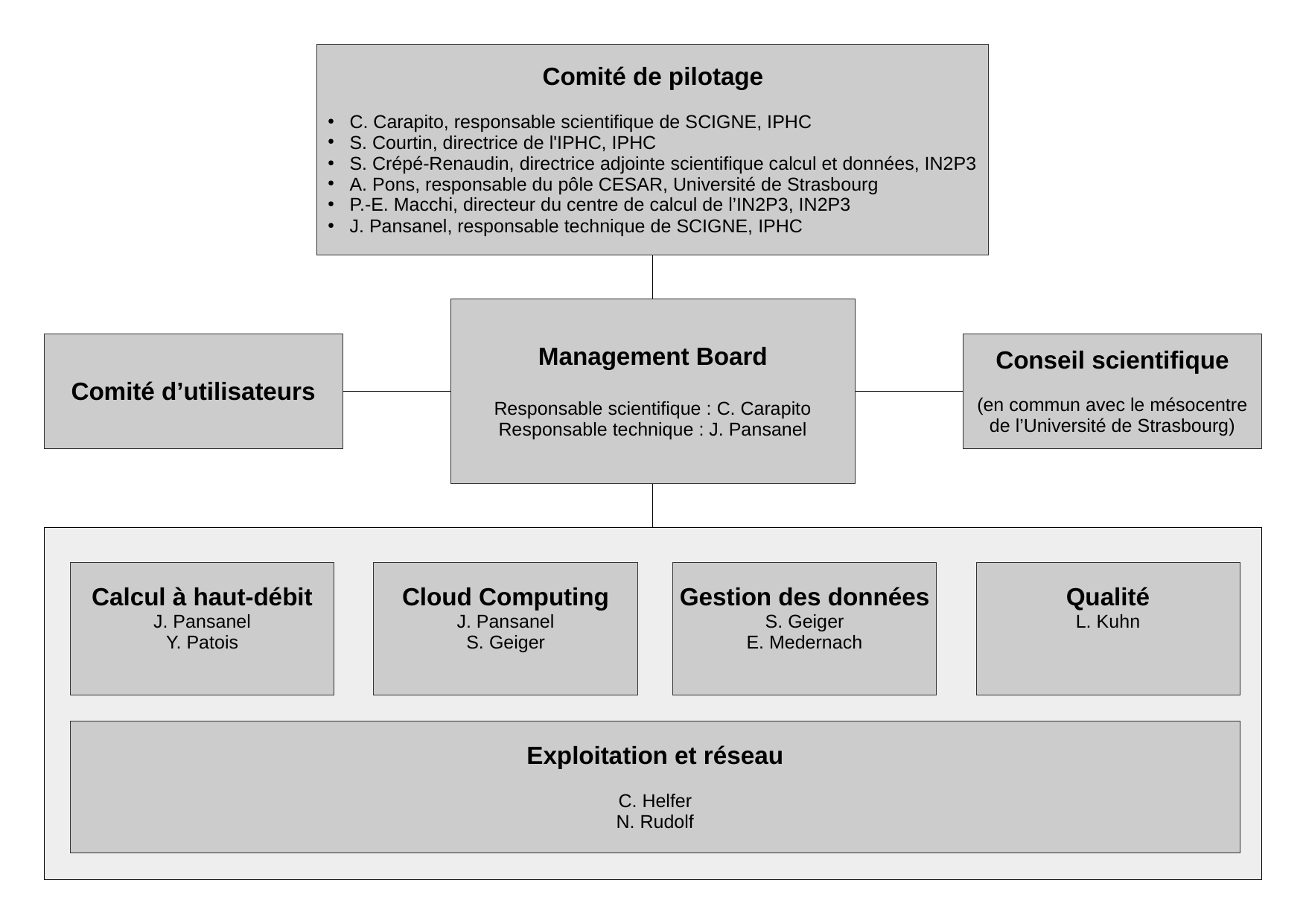
Gouvernance
Le pilotage de la plateforme est assuré par un comité de pilotage où siège un représentant des partenaires institutionnels de l’IPHC, ainsi que les responsables technique et scientifique de la plateforme.
La composition actuelle de ce comité est la suivante :
- Christine CARAPITO, responsable scientifique de SCIGNE, IPHC
- Sandrine COURTIN, directrice de l’IPHC, IPHC
- Sabine CRÉPÉ-RENAUDIN, directrice adjointe scientifique calcul et données, IN2P3
- Arthur PONS, responsable du pôle CESAR, Université de Strasbourg
- Pierre-Étienne MACCHI, directeur du Centre de Calcul de l’IN2P3, IN2P3
- Jérôme PANSANEL, responsable technique de SCIGNE, IPHC
En complément, la définition des évolutions de la plateforme (nouveaux services, évolution des infrastructures, …), le montage des formations et le choix des orientations stratégiques sont réalisés en collaboration et en accord avec les principaux utilisateurs de la plateforme.
Partenariats et Financements
Le dynamisme et l’innovation de la plateforme SCIGNE sont permis grâce à l’implication de partenaires locaux, nationaux et internationaux.
Partenaires locaux
Partenaires nationaux



Partenaires internationaux


![]()
SCIGNE: Open, secure, and seamless scientific computing for everyone